Deploy an MLflow Registered Model Version using InfinStor¶
Initiating a MLflow run that logs a model¶
In this example, we will log a huggingface sentiment analysis pipeline as a MLflow model artifact. Then we will create a Registered Model Version using this logged model artifact. Finally, we will deploy this model in the InfinStor Compute Engine.
First, here's how we clone the github repo:
git clone https://github.com/infinstor/huggingface-sentiment-analysis-to-mlflow.git
Next we run the python code that logs huggingface sentiment analysis pipeline as a MLflow model artifact
(base) workstation:~/working/huggingface-sentiment-analysis-to-mlflow$ python ./log_model.py
No model was supplied, defaulted to distilbert-base-uncased-finetuned-sst-2-english (https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english)
Downloading: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 255M/255M [00:12<00:00, 21.7MB/s]
Downloading: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 48.0/48.0 [00:00<00:00, 26.5kB/s]
Downloading: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 226k/226k [00:00<00:00, 1.01MB/s]
2022-02-03 16:43:42,497 - 10384 - botocore.credentials - INFO - Found credentials in shared credentials file: ~/.aws/credentials
(base) workstation:~/working/huggingface-sentiment-analysis-to-mlflow$
Using the MLflow UI to create a Registered Model Version from the run's model artifact¶
Create a new Registered Model by browsing to the Models tab in the MLflow UI and then clicking on the Create Model button.

Next, go to the experiment run page for the recent run and register the model as a Registered Model Version by pressing the Register Model button
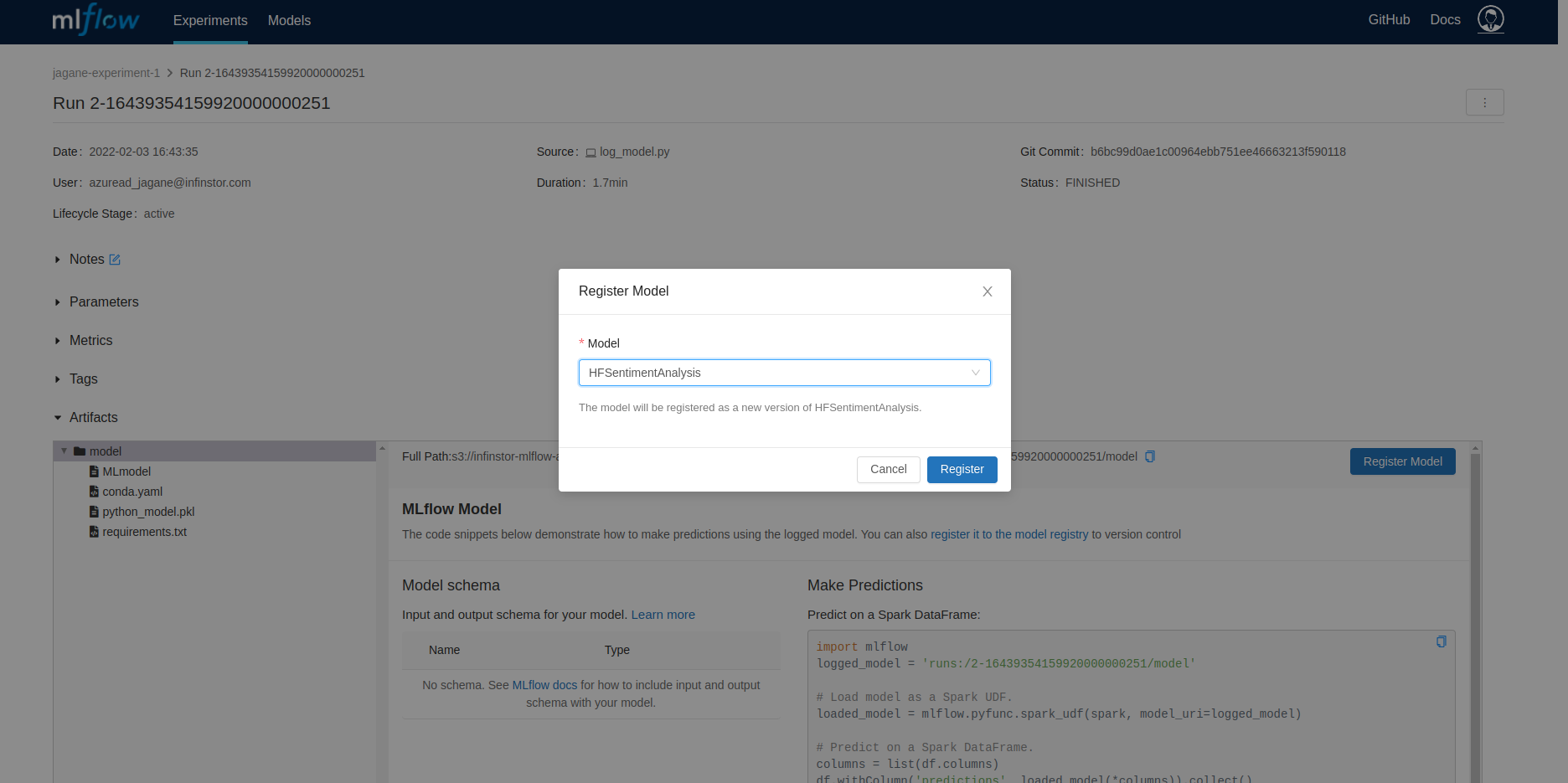
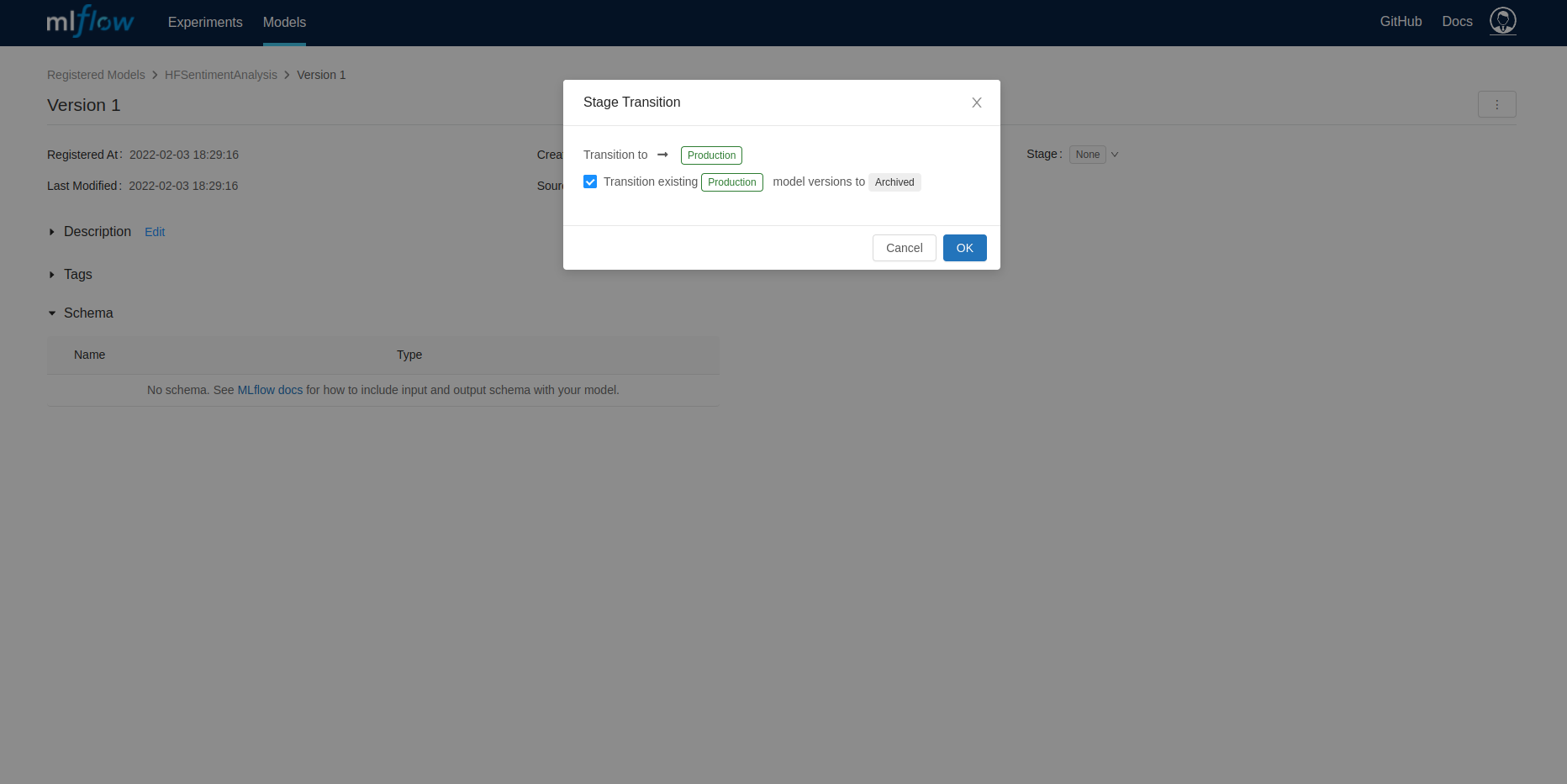
Move this newly registered model version to Staging or Production
Using the InfinStor Jupyterlab sidebar to Deploy Model¶
Click on the Deploy Model group in the InfinStor sidebar and press the Deploy button Choose the recently created Model, HFSentimentAnalysis in this example, and click Next

Identify the version you want to deploy and click on the Deploy button next to the version

Choose a name, Cloud and VM Type in this next step

Use Manage Resources to view running VMs. If you choose the Manage Resources group in the sidebar, the sidebar will display a flyout with a listing of all of your VM
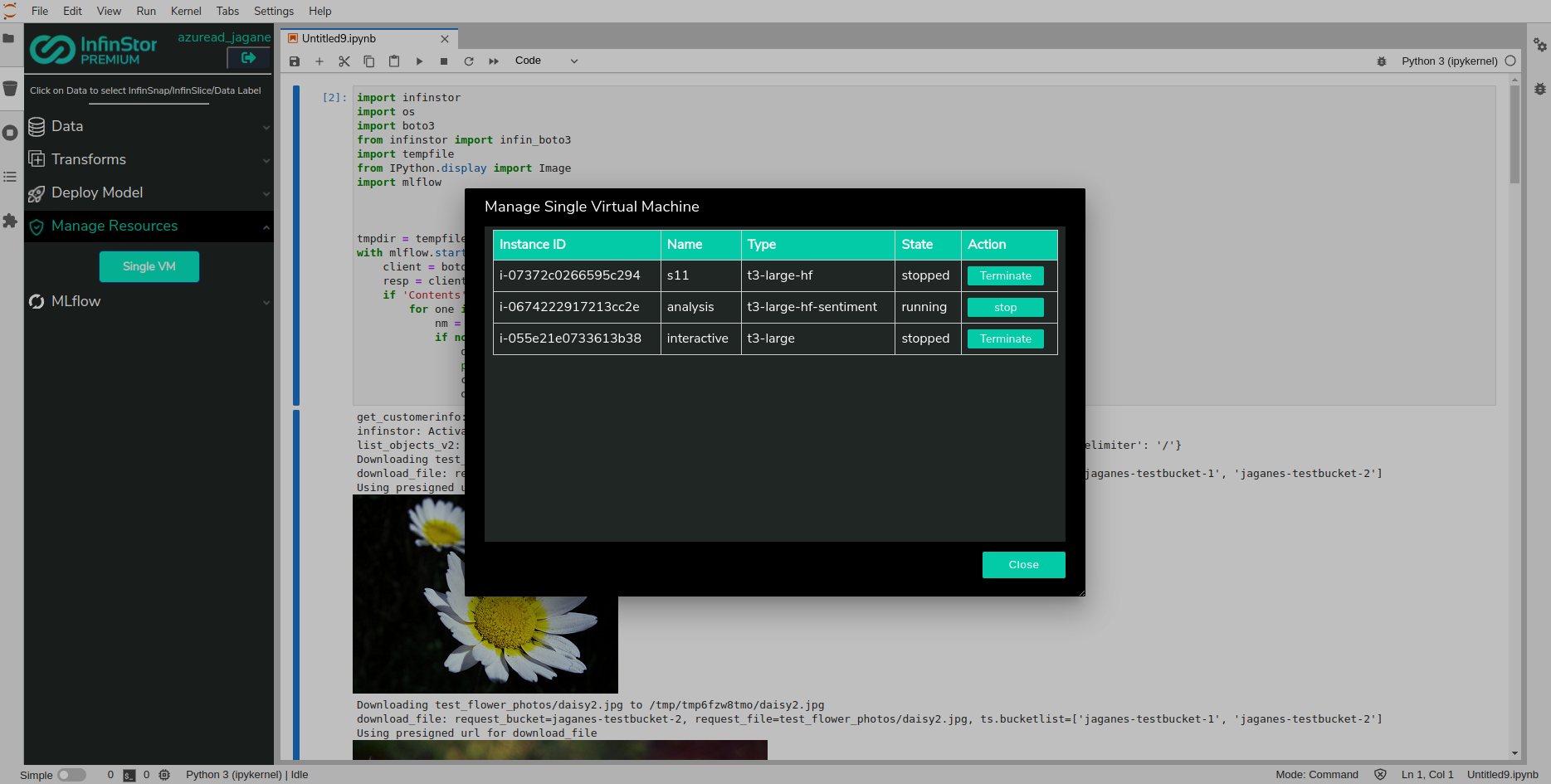
In just a few minutes, the VM will have initialized and a running instance of the Model is available to you for inference at 0.0.0.0:5000. Note that there is no port forwarding from your Internet Gateway or NAT device to this machine, so you will need to access it from other VMs in the same VPC
Here is an example of a successful inference request. In this example, the server is running in the internal IP address 172.31.95.118, port 5000:
$ curl -X POST -H "Content-Type:application/json; format=pandas-split" --data '{"columns":["text"],"data":[["This is meh weather"], ["This is great wuther"]]}' http://172.31.95.118:5000/invocations
[{"text": "This is meh weather", "label": "NEGATIVE", "score": 0.753341794013977}, {"text": "This is great wuther", "label": "POSITIVE", "score": 0.9984263181686401}]
Note
The VM is locked down from a network perspective. You need to create a security group that permits port 5000 in, and then you must associate this security group with the VM. Only then will the inference request succeed