InfinStor Jupyterlab Integration - Concepts and High Level Architecture¶
InfinStor capabilities are accessible to Jupyterlab directly from their Jupyterlab browser window by means of a sidebar.
Components¶
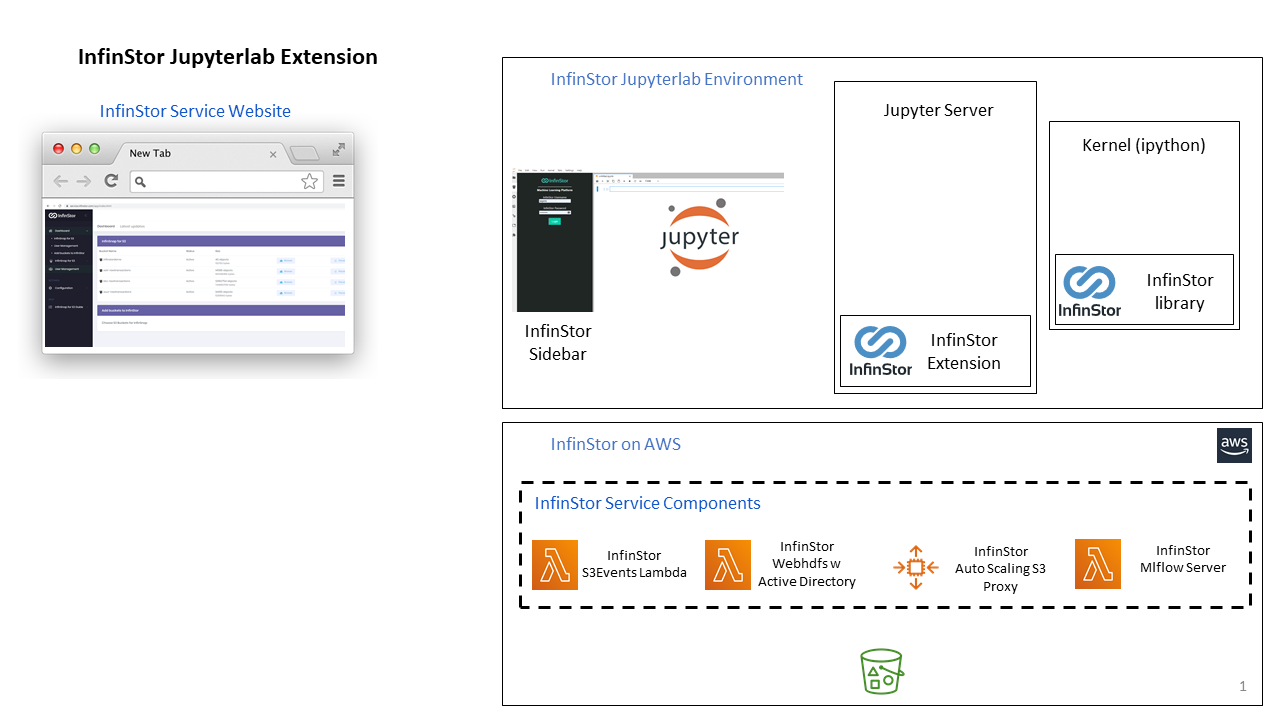
InfinStor Sidebar in Jupyterlab¶
Jupyterlab is a sophisticated application consisting of three distinct pieces of software. InfinStor Jupyterlab extension requires code to be loaded into each of these three pieces of software
- Jupyterlab server: A web server which serves up content to a browser based interface
- The browser based interface
- The web server then sends commands and python snippets to the ipython kernel for execution
InfinStor extension to Jupyterlab server¶
This is a python package installed using 'pip install jupyterlab_infinstor'. It adds to the capabilities of the jupyterlab server.
InfinStor Sidebar Web Browser Component installed using npmjs¶
InfinStor Jupyterlab sidebar is a convenient UI tool for accessing InfinStor capabilities right from within the Jupyterlab user interface. It is usually installed using 'npm install -d jupyterlab-infinstor'
The InfinStor SDK¶
This is the pip package installed as 'pip install infinstor'. This package needs to be installed in the jupyterlab server process, any ipython kernels started by jupyterlab and the python processing started up in the cloud based Single VM.