InfinStor Service Versions¶
InfinStor ML Platform is a cloud service sold as three different versions:
- InfinStor Starter with MLflow: Free MLflow as a hosted service
- InfinStor Premium: Adds data and compute management tools
- InfinStor Enterprise: All of premium features, in your own AWS account
Premium Concepts and High Level Architecture¶
InfinStor Premium adds a number of interesting capabilities to InfinStor Starter. The following is a non-comprehensive list: - InfinSnap fine grained snapshots of Cloud Object Stores - InfinSlice fine grained slices of data from Cloud Object Stores - Tensor Snapshots caching of tensorflow tf.data.DataSet and pytorch DataSet for quick iteration - Capture jupyter cells as transforms and run them scaled out in the cloud in EMR
InfinSnap¶
InfinSnap is innovative technology for creating fine grained bucket wide snapshots of S3 data. Most applications treat S3 like a hierarchical file system and read multiple objects from S3, e.g. read all files in a directory for a machine learning training run, or an analytics query. In these types of uses, bucket wide snapshots are much more valuable than S3 native object versioning.
InfinSlice¶
InfinSlice is slices of data between a begin and an end time - this is useful for activities such as Incremental Training and Data Drift Protection.
InfinStor S3 InfinSnap and InfinSlice are completely non-invasive - they use S3 Events to construct snapshot metadata. InfinStor does not require a proxy to be installed between the ingest process and the S3 bucket. Therefore, it requires no disruption to your ingest pipeline.
On the read side, the InfinStor platform offers two ways to access the data - auto scaling s3 proxy, and webhdfs emulation. Each method has its advantages.
Architecture¶
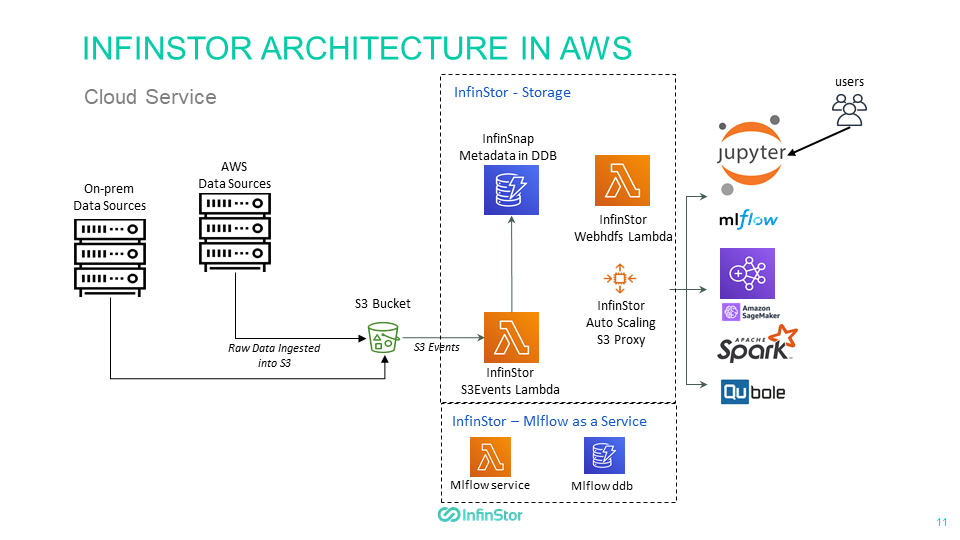
- Pictured here are two sources of data for the S3 bucket - on-premise, and AWS based
- When S3 InfinSnap is enabled for your existing S3 bucket, the InfinStor service will do the following
- Turn on S3 Object versioning, if it was not already on
- Turn on S3 Events and point the events at a SQS queue that the InfinStor service will read from
- When an Object Create or Object Delete is performed on the S3 bucket, the InfinStor service creates InfinSnap metadata
- Cloud based ML and Analytics applications such as tensorflow, mlflow, EMR, Qubole and Spark can consume the backed up data
- InfinSnap fine grained snapshots are available so read applications can get consistent read-only views of the data from any point in time in the past